Publications
(*) denotes equal contribution
2025
-
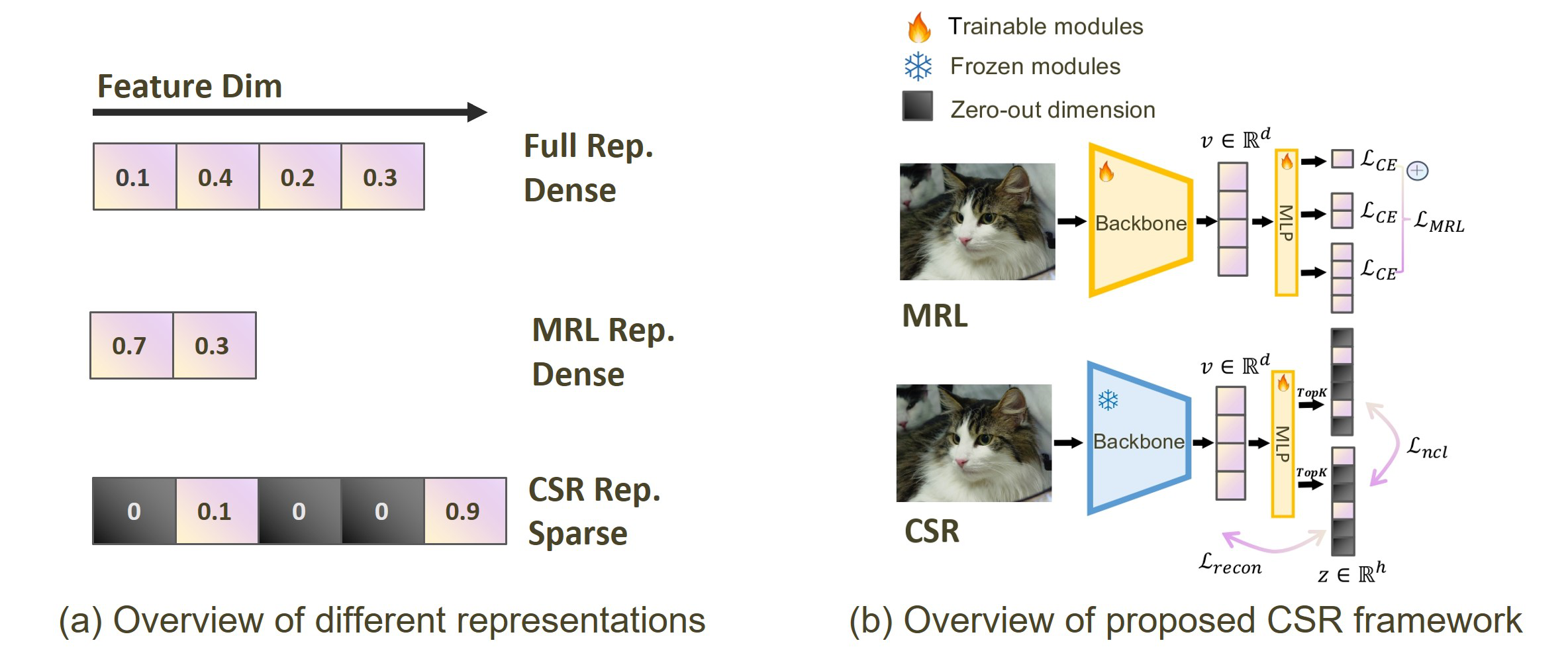 Beyond Matryoshka: Revisiting Sparse Coding for Adaptive RepresentationTiansheng Wen*, Yifei Wang*, zequn Zeng, Zhong Peng, Yudi Su, Xinyang Liu, Bo Chen, Hongwei Liu, Stefanie Jegelka, and Chenyu YouForty-Second International Conference on Machine Learning (ICML), 2025Oral Presentation [Top 1%]
Beyond Matryoshka: Revisiting Sparse Coding for Adaptive RepresentationTiansheng Wen*, Yifei Wang*, zequn Zeng, Zhong Peng, Yudi Su, Xinyang Liu, Bo Chen, Hongwei Liu, Stefanie Jegelka, and Chenyu YouForty-Second International Conference on Machine Learning (ICML), 2025Oral Presentation [Top 1%]Many large-scale systems rely on high-quality deep representations (embeddings) to facilitate tasks like retrieval, search, and generative modeling. Matryoshka Representation Learning (MRL) recently emerged as a solution for adaptive embedding lengths, but it requires full model retraining and suffers from noticeable performance degradations at short lengths. In this paper, we show that sparse coding offers a compelling alternative for achieving adaptive representation with minimal overhead and higher fidelity. We propose Contrastive Sparse Representation (CSR), a method that sparsifies pre-trained embeddings into a high-dimensional but selectively activated feature space. By leveraging lightweight autoencoding and task-aware contrastive objectives, CSR preserves semantic quality while allowing flexible, cost-effective inference at different sparsity levels. Extensive experiments on image, text, and multimodal benchmarks demonstrate that CSR consistently outperforms MRL in terms of both accuracy and retrieval speed-often by large margins-while also cutting training time to a fraction of that required by MRL. Our results establish sparse coding as a powerful paradigm for adaptive representation learning in real-world applications where efficiency and fidelity are both paramount.
-
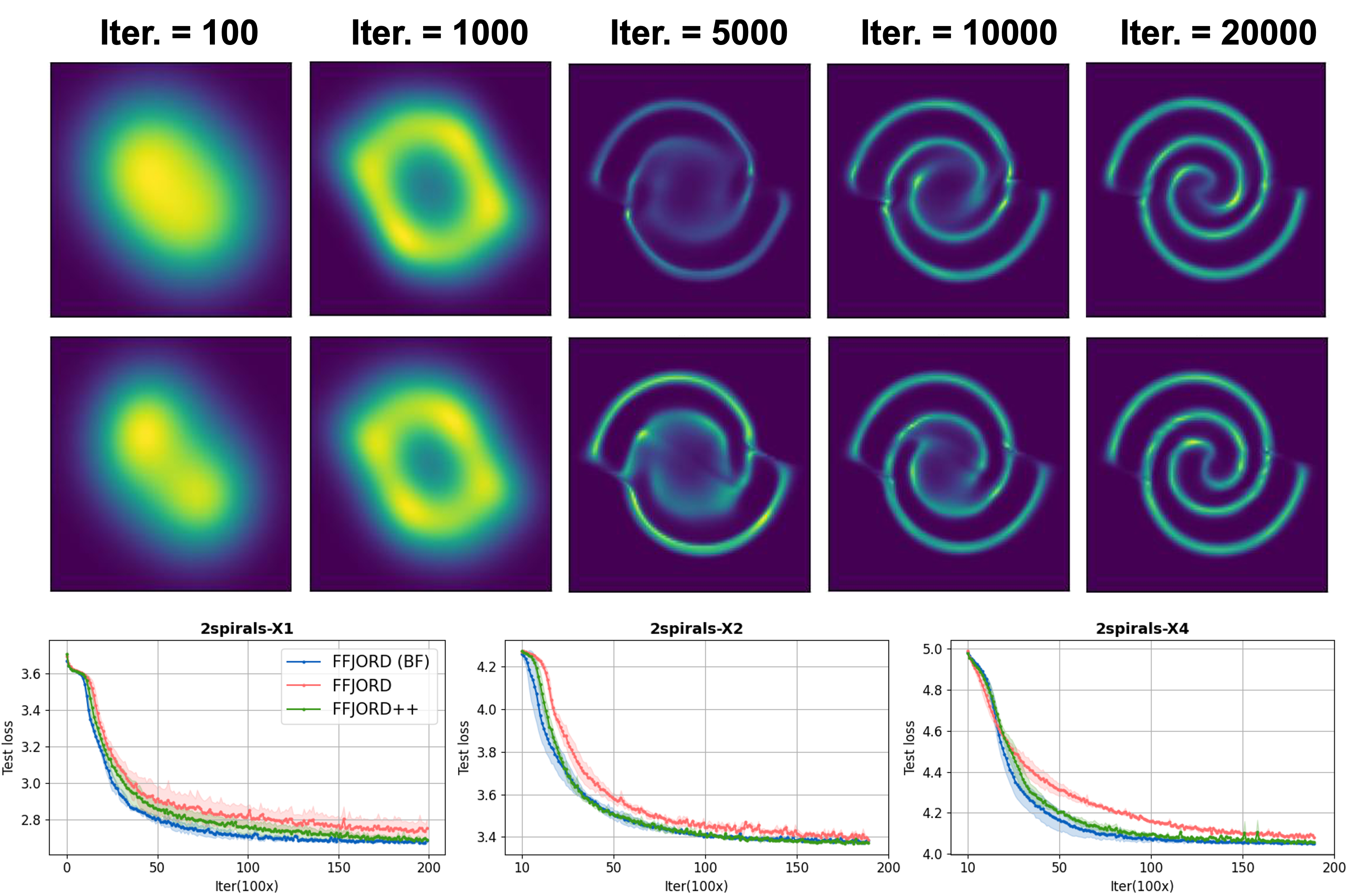 Optimal Stochastic Trace Estimation in Generative ModelingThe 28th International Conference on Artificial Intelligence and Statistics (AISTATS), 2025
Optimal Stochastic Trace Estimation in Generative ModelingThe 28th International Conference on Artificial Intelligence and Statistics (AISTATS), 2025Hutchinson estimators are widely employed in training divergence-based likelihoods for diffusion models to ensure optimal transport (OT) properties. However, this estimator often suffers from high variance and scalability concerns. To address these challenges, we investigate Hutch++, an optimal stochastic trace estimator for generative models, designed to minimize training variance while maintaining transport optimality. Hutch++ is particularly effective for handling ill-conditioned matrices with large condition numbers, which commonly arise when high-dimensional data exhibits a low-dimensional structure. To mitigate the need for frequent and costly QR decompositions, we propose practical schemes that balance frequency and accuracy, backed by theoretical guarantees. Our analysis demonstrates that Hutch++ leads to generations of higher quality. Furthermore, this method exhibits effective variance reduction in various applications, including simulations, conditional time series forecasts, and image generation.
-
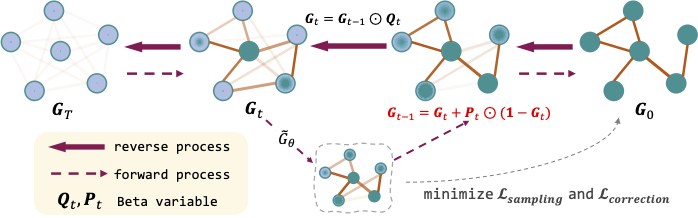 Advancing Graph Generation through Beta DiffusionXinyang Liu*, Yilin He*, Bo Chen, and Mingyuan ZhouThe Thirteenth International Conference on Learning Representations (ICLR), 2025
Advancing Graph Generation through Beta DiffusionXinyang Liu*, Yilin He*, Bo Chen, and Mingyuan ZhouThe Thirteenth International Conference on Learning Representations (ICLR), 2025Diffusion models have demonstrated effectiveness for generating natural images and have since been adapted to generate diverse types of data, including graphs. While this emerging family of diffusion-based graph generative models has shown remarkable performance gains over predecessors that rely on variational autoencoders or generative adversarial networks, it is important to note that the majority of these models utilize Gaussian or categorical-based diffusion processes, which may encounter difficulties when modeling sparse and long-tailed data distributions. In our work, we introduce Graph Beta Diffusion (GBD), a diffusion-based generative model adept at modeling diverse graph structures. Focusing on the sparse and range-bounded characteristics of graph adjacency matrices, GBD employs a beta diffusion process to ensure that the initial distribution aligns with the beta distribution, which is well-suited for modeling such data types. To enhance the realism of generated graphs further, we introduce a modulation technique that stabilizes the generation of important graph structures while maintaining flexibility for the rest. The superior performance of GBD in generating graphs, as demonstrated across three generic graph benchmarks and two biochemical graph benchmarks, underscores its effectiveness in capturing the complexities of real-world graph data.
2024
-
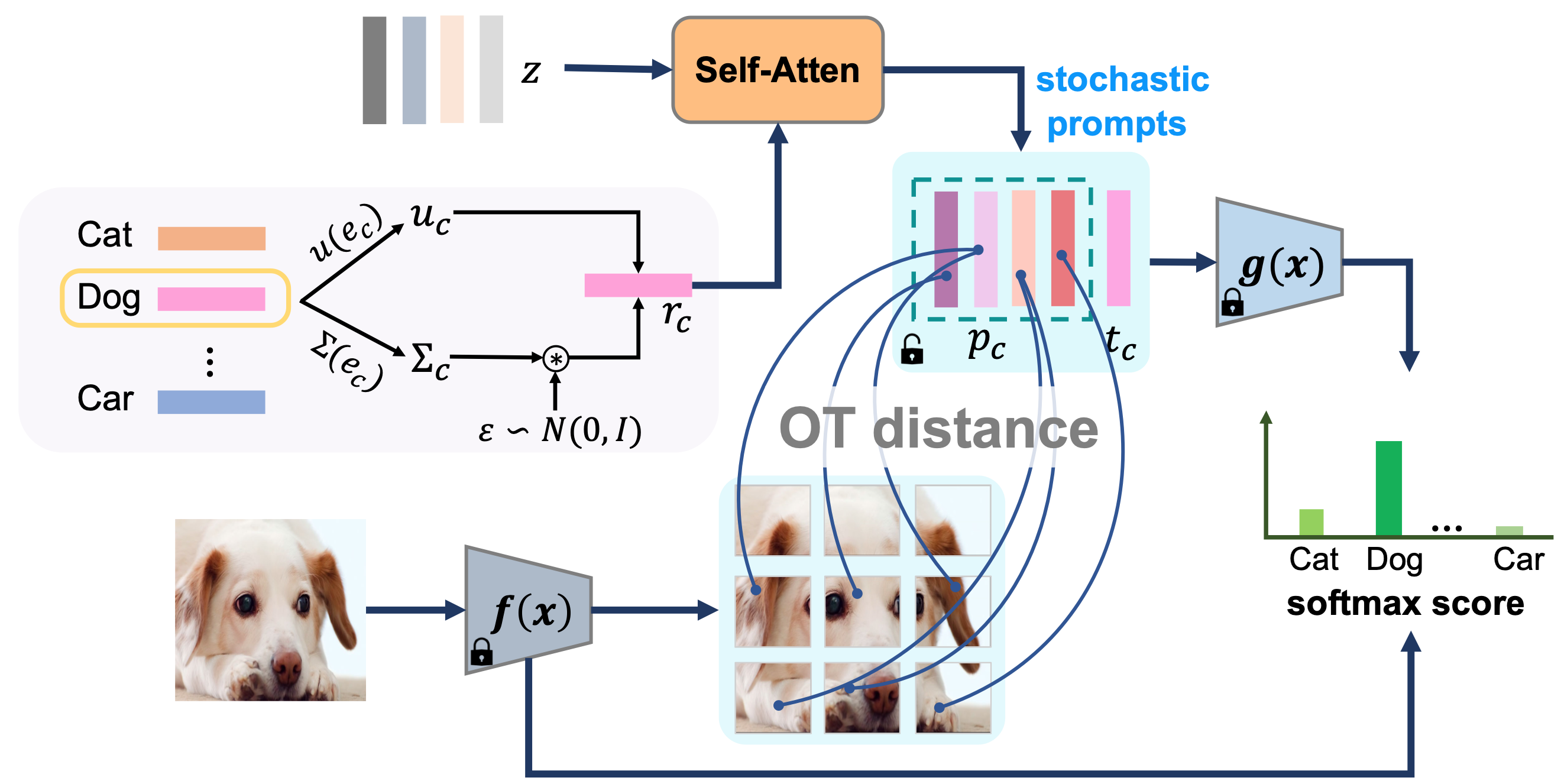 Patch-Prompt Aligned Bayesian Prompt Tuning for Vision-Language ModelsXinyang Liu*, Dongsheng Wang*, Bowei Fang, Miaoge Li, Zhibin Duan, Yishi Xu, Bo Chen, and Mingyuan ZhouProceedings of the 40th Conference on Uncertainty in Artificial Intelligence (UAI), 2024
Patch-Prompt Aligned Bayesian Prompt Tuning for Vision-Language ModelsXinyang Liu*, Dongsheng Wang*, Bowei Fang, Miaoge Li, Zhibin Duan, Yishi Xu, Bo Chen, and Mingyuan ZhouProceedings of the 40th Conference on Uncertainty in Artificial Intelligence (UAI), 2024For downstream applications of vision-language pre-trained models, there has been significant interest in constructing effective prompts. Existing works on prompt engineering, which either require laborious manual designs or optimize the prompt tuning as a point estimation problem, may fail to describe diverse characteristics of categories and limit their applications. We introduce a Bayesian probabilistic resolution to prompt tuning, where the label-specific stochastic prompts are generated hierarchically by first sampling a latent vector from an underlying distribution and then employing a lightweight generative model. Importantly, we semantically regularize the tuning process by minimizing the statistical distance between the visual patches and linguistic prompts, which pushes the stochastic label representations to faithfully capture diverse visual concepts, instead of overfitting the training categories. We evaluate the effectiveness of our approach on four tasks: few-shot image recognition, base-to-new generalization, dataset transfer learning, and domain shifts. Extensive results over 15 datasets show promising transferability and generalization performance of our proposed model, both quantitatively and qualitatively.
-
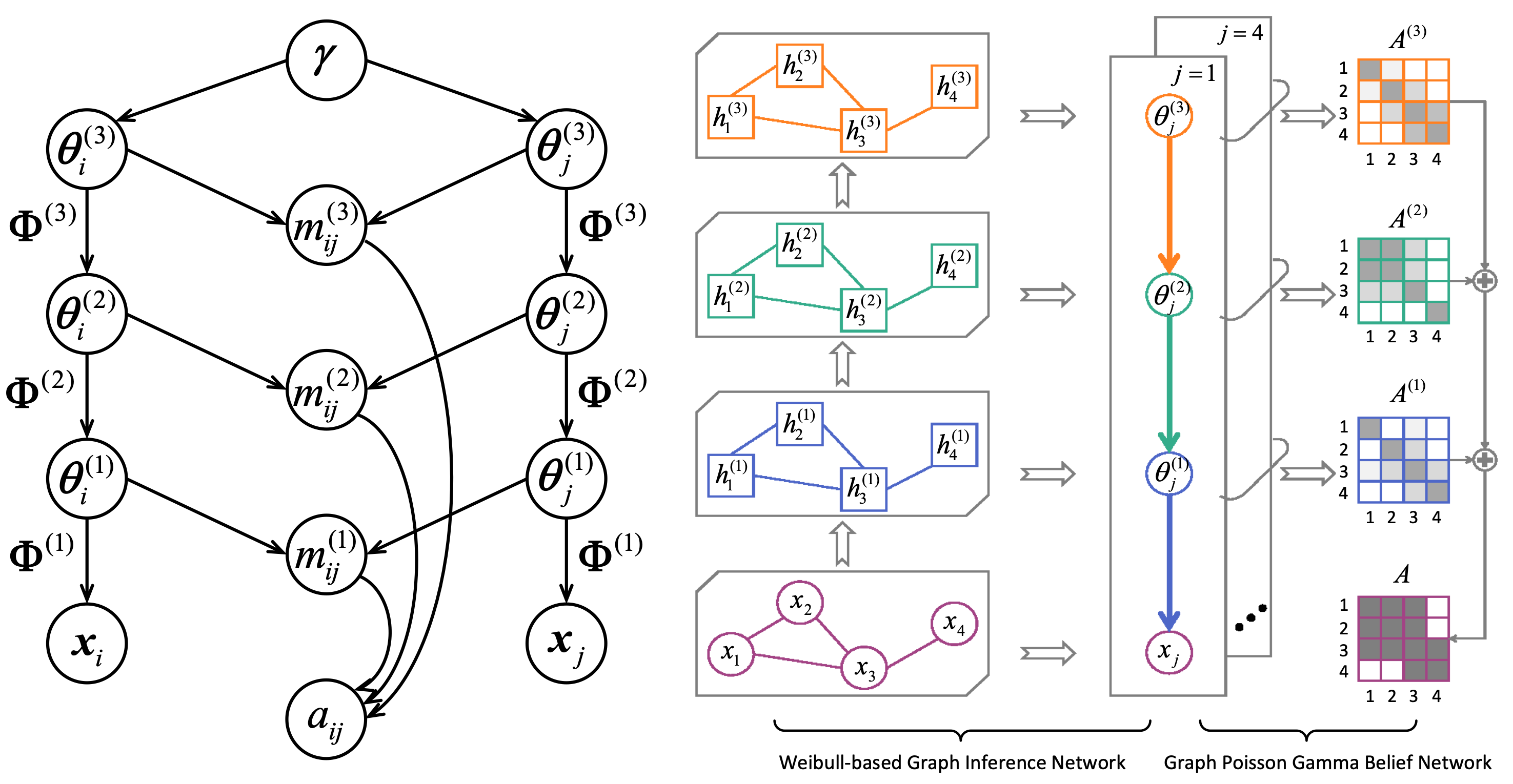 Scalable Weibull Graph Attention Autoencoder for Modeling Document NetworksChaojie Wang*, Xinyang Liu*, Dongsheng Wang, Hao Zhang, Bo Chen, and Mingyuan ZhouArXiv 2410.09696, 2024, 2024
Scalable Weibull Graph Attention Autoencoder for Modeling Document NetworksChaojie Wang*, Xinyang Liu*, Dongsheng Wang, Hao Zhang, Bo Chen, and Mingyuan ZhouArXiv 2410.09696, 2024, 2024Although existing variational graph autoencoders (VGAEs) have been widely used for modeling and generating graph-structured data, most of them are still not flexible enough to approximate the sparse and skewed latent node representations, especially those of document relational networks (DRNs) with discrete observations. To analyze a collection of interconnected documents, a typical branch of Bayesian models, specifically relational topic models (RTMs), has proven their efficacy in describing both link structures and document contents of DRNs, which motives us to incorporate RTMs with existing VGAEs to alleviate their potential issues when modeling the generation of DRNs. In this paper, moving beyond the sophisticated approximate assumptions of traditional RTMs, we develop a graph Poisson factor analysis (GPFA), which provides analytic conditional posteriors to improve the inference accuracy, and extend GPFA to a multi-stochastic-layer version named graph Poisson gamma belief network (GPGBN) to capture the hierarchical document relationships at multiple semantic levels. Then, taking GPGBN as the decoder, we combine it with various Weibull-based graph inference networks, resulting in two variants of Weibull graph auto-encoder (WGAE), equipped with model inference algorithms. Experimental results demonstrate that our models can extract high-quality hierarchical latent document representations and achieve promising performance on various graph analytic tasks.
2023
-
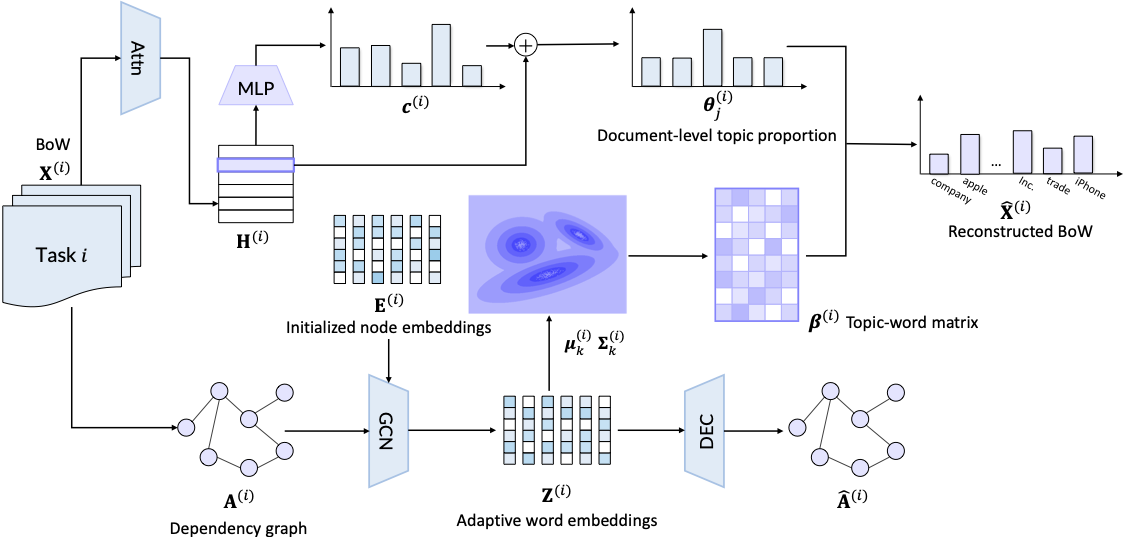 Context-guided Embedding Adaptation for Effective Topic Modeling in Low-Resource RegimesThe 37th Conference on Neural Information Processing Systems (NeurIPS), 2023
Context-guided Embedding Adaptation for Effective Topic Modeling in Low-Resource RegimesThe 37th Conference on Neural Information Processing Systems (NeurIPS), 2023Embedding-based neural topic models have been shown as superior options for few-shot topic modeling. However, existing approaches treat the static word embeddings learned from source tasks as transferable knowledge which can be directly applied to the target task, ignoring the fact that word meanings can vary across tasks with different contexts, thus leading to suboptimal results when adapting to new tasks with novel contexts. To address the issue, in this paper, we propose an effective approach for topic modeling under the low-resource regime, the core of which is the adaptive generation of semantic matching word embeddings by integrating the contextual information of each task. Concretely, we introduce a variational graph autoencoder to learn task-specific word embeddings based on the dependency graph refined from the context of each task, with a learnable Gaussian mixture prior to capture the clustering structure of distributed word representations. This is naturally connected to topic modeling by regarding each component of the mixture as the representation of a topic, which facilitates the discovery of diverse topics and the fast adaptation to novel tasks. Both quantitative and qualitative experiments demonstrate the superiority of our method against established topic models.
-
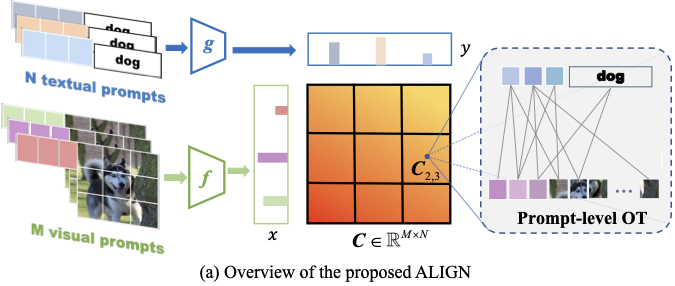 Tuning Multi-mode Token-level Prompt Alignment across ModalitiesThe 37th Conference on Neural Information Processing Systems (NeurIPS), 2023
Tuning Multi-mode Token-level Prompt Alignment across ModalitiesThe 37th Conference on Neural Information Processing Systems (NeurIPS), 2023Prompt tuning pre-trained vision-language models have demonstrated significant potential in improving open-world visual concept understanding. However, prior works only primarily focus on single-mode (only one prompt for each modality) and holistic level (image or sentence) semantic alignment, which fails to capture the sample diversity, leading to sub-optimal prompt discovery. To address the limitation, we propose a multi-mode token-level tuning framework that leverages the optimal transportation to learn and align a set of prompt tokens across modalities. Specifically, we rely on two essential factors: 1) multi-mode prompts discovery, which guarantees diverse semantic representations, and 2) token-level alignment, which helps explore fine-grained similarity. Thus, the similarity can be calculated as a hierarchical transportation problem between the modality-specific sets. Extensive experiments on popular image recognition benchmarks show the superior generalization and few-shot abilities of our approach. The qualitative analysis demonstrates that the learned prompt tokens have the ability to capture diverse visual concepts.
-
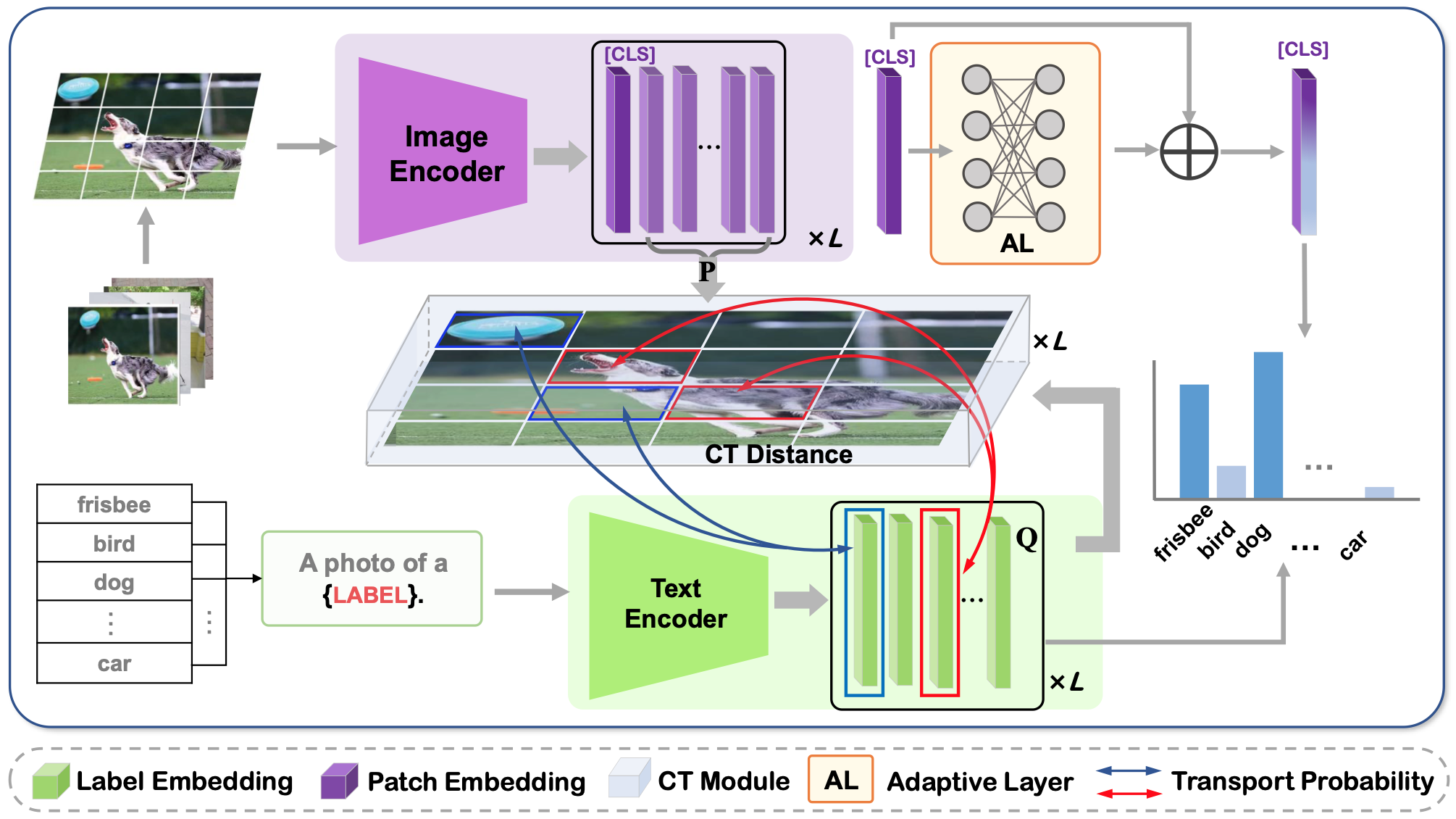 PatchCT: Aligning Patch Set and Label Set with Conditional Transport for Multi-Label Image ClassificationProceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), 2023
PatchCT: Aligning Patch Set and Label Set with Conditional Transport for Multi-Label Image ClassificationProceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), 2023Multi-label image classification is a prediction task that aims to identify more than one label from a given image. This paper considers the semantic consistency of the latent space between the visual patch and linguistic label domains and introduces the conditional transport (CT) theory to bridge the acknowledged gap. While recent cross-modal attention-based studies have attempted to align such two representations and achieved impressive performance, they required carefully-designed alignment modules and extra complex operations in the attention computation. We find that by formulating the multi-label classification as a CT problem, we can exploit the interactions between the image and label efficiently by minimizing the bidirectional CT cost. Specifically, after feeding the images and textual labels into the modality-specific encoders, we view each image as a mixture of patch embeddings and a mixture of label embeddings, which capture the local region features and the class prototypes, respectively. CT is then employed to learn and align those two semantic sets by defining the forward and backward navigators. Importantly, the defined navigators in CT distance model the similarities between patches and labels, which provides an interpretable tool to visualize the learned prototypes. Extensive experiments on three public image benchmarks show that the proposed model consistently outperforms the previous methods.
-
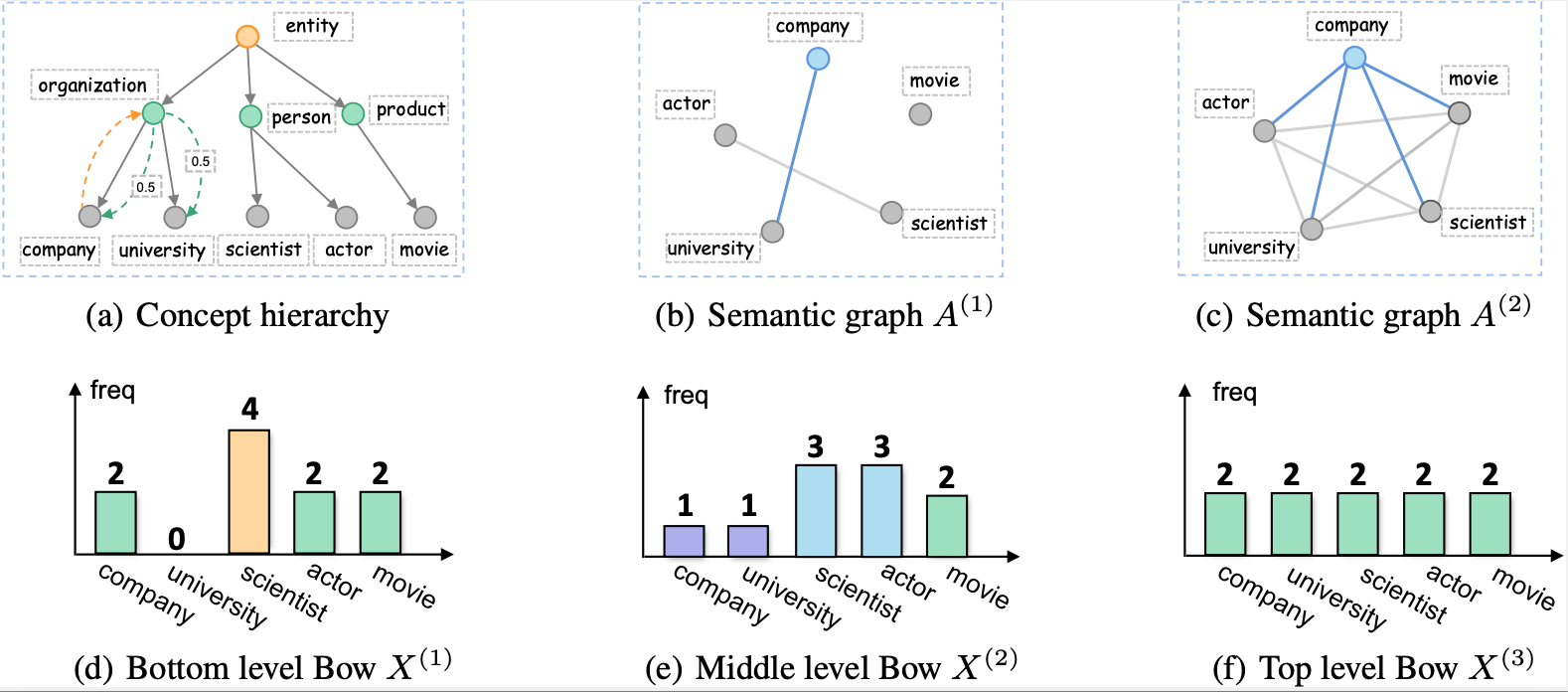 Bayesian Progressive Deep Topic Model with Knowledge Informed Textual Data Coarsening ProcessThe 40th International Conference on Machine Learning (ICML), 2023
Bayesian Progressive Deep Topic Model with Knowledge Informed Textual Data Coarsening ProcessThe 40th International Conference on Machine Learning (ICML), 2023Deep topic models have shown an impressive ability to extract multi-layer document latent representations and discover hierarchical semantically meaningful topics. However, most deep topic models are limited to the single-step generative process, despite the fact that the progressive generative process has achieved impressive performance in modeling image data. To this end, in this paper, we propose a novel progressive deep topic model that consists of a knowledge-informed textural data coarsening process and a corresponding progressive generative model. The former is used to build multi-level observations ranging from concrete to abstract, while the latter is used to generate more concrete observations gradually. Additionally, we incorporate a graph-enhanced decoder to capture the semantic relationships among words at different levels of observation. Furthermore, we perform a theoretical analysis of the proposed model based on the principle of information theory and show how it can alleviate the wellknown “latent variable collapse” problem. Finally, extensive experiments demonstrate that our proposed model effectively improves the ability of deep topic models, resulting in higher-quality latent document representations and topics.